菠菜担保平台王智彬老师课题组在3月1日举行的计算机并行计算领域顶会PPoPP 2025上首次以南大作为第一单位在该会议发表论文,提出GPU上快速社区检测方法——GALA。
论文地址:https://dl.acm.org/doi/pdf/10.1145/3710848.3710884
研究背景
在图计算众多子领域中,社区检测作为图挖掘与分析的一个重要分支,在揭示图聚集结构上发挥着重大作用。社区检测旨在挖掘图中的内在聚集结构,将紧密相连的顶点划分为同一社区,从而揭示出图的模块化特征。现实中,社交网络、科研合作、金融网络等,都可以利用社区检测技术帮助人们更好地理解图网络的整体构成和功能分布。
在社区检测方法中,Louvain算法作为模块度优化算法中的典型代表,采用贪婪的局部优化策略,通过层次聚合有效提升整体模块度,是处理大规模图社区检测的最常用方法之一。简单来说,Louvain算法分为两个阶段交替进行:第一阶段是模块度优化,通过贪婪策略移动顶点聚合成社区;第二阶段是图的聚合,将社区聚合成新的顶点再进行下一轮的计算。Louvain算法因其高效性、易实现以及在大规模图上良好的扩展性而从一众社区检测方法中脱颖而出,被广泛应用。

图 1 Louvain算法过程
研究动机
随着图规模的不断增长,Louvain 算法的顺序实现可能效率和可扩展性不足。这种低效率源于计算密集型和内存密集型工作负载,例如评估模块度增益以评估顶点迁移到新社区的可能性。为了克服这些挑战,已经开发了针对多核 CPU 和 GPU的并行解决方案。然而,现有的实现存在两个关键问题:
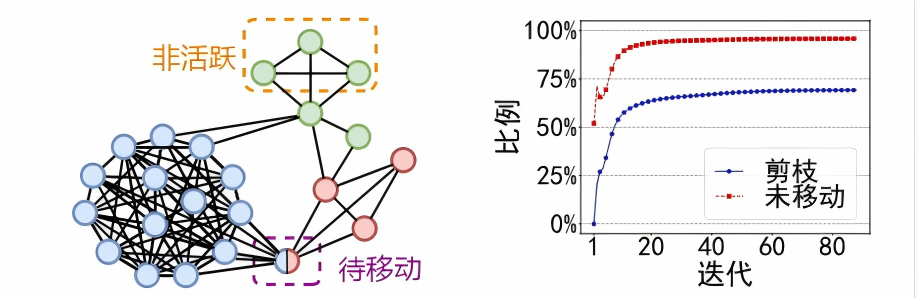
剪枝不准确或不足:在大规模图中,Louvain 算法可能需要大量迭代才能收敛,如图 2(b) 所示。随着迭代的进行,我们观察到很大一部分(高达 95%)的顶点仍保留在其当前社区中,即未移动的顶点。如果我们能够预测这些未移动的顶点并在迭代之前将其标记为非活动顶点,则有机会跳过这些处理。例如,图 2(a) 中橙色虚线包围的三个绿色顶点位于社区的核心,即它们的邻居都不属于其他社区,并且它们的邻居在上一次迭代中未移动。因此,这三个顶点可以标记为非活动顶点。我们观察到,现有的仅基于移动信息的启发式剪枝策略存在双重缺陷:它们要么导致次优解,要么无法充分识别未移动的顶点。幸运的是,Louvain 算法的并行实现所使用的批量同步并行 (BSP) 模型,除了单纯的顶点移动之外,还能提供更丰富的信息,从而能够开发高效的修剪策略。
低效的中间状态管理:Louvain 算法需要一组更复杂的状态来追踪顶点与其邻近社区之间的权重。早期在 GPU 上的尝试使用全局内存来存储中间状态。这导致了严重的性能瓶颈,影响了整体性能。后续研究使用共享内存来维护小度数顶点的中间状态,但仍然没有充分利用 GPU 的内存层次结构。
(a) (b)
图2 剪枝示例
解决方案
在本文中,我们提出了 GALA,即 GPU Accelerated Louvain Algorithm 算法的缩写。
(一) 基于模块度增益的剪枝策略
GALA 集成了一种基于模块度增益的新颖剪枝策略,以在保持最优性的同时降低计算成本。如果一个顶点在其当前社区内已经获得足够高的模块度增益,则下一次迭代中的移动是多余的。BSP 模型提供的附加状态使得通过移动到其他社区可以获得最大可能模块度增益的更严格的上限。通过将上限与当前模块度增益进行比较,剪枝策略可以实现较低的误报率,同时避免误报。如图 2(b) 所示,随着迭代的进行,高达 69% 的顶点被剪枝。观察到重新计算顶点与其当前社区之间的权重成为新的瓶颈,我们进一步提出了一种高效的社区权重更新方法,以避免不必要的重新计算。
(二) GPU内存管理
为了有效利用 GPU 中的内存层次结构和附加并行性,我们为 GALA 开发了一种新颖的内存管理策略。考虑到各级内存的不同特性,我们提出了两种 GPU 内核,即基于 shuffle 和基于 hash 的内核,以优化关键中间状态的管理。基于 shuffle 的内核维护 Warp 内线程寄存器之间的状态,并利用 Warp 级原语对状态进行 shuffle。相比之下,基于 hash 的内核利用共享内存和全局内存来维护中间状态,并使用优先访问共享内存的分层哈希表。此外,我们将计算图分布到多个 GPU 上,并提出了一种自适应策略来扩展 GALA。
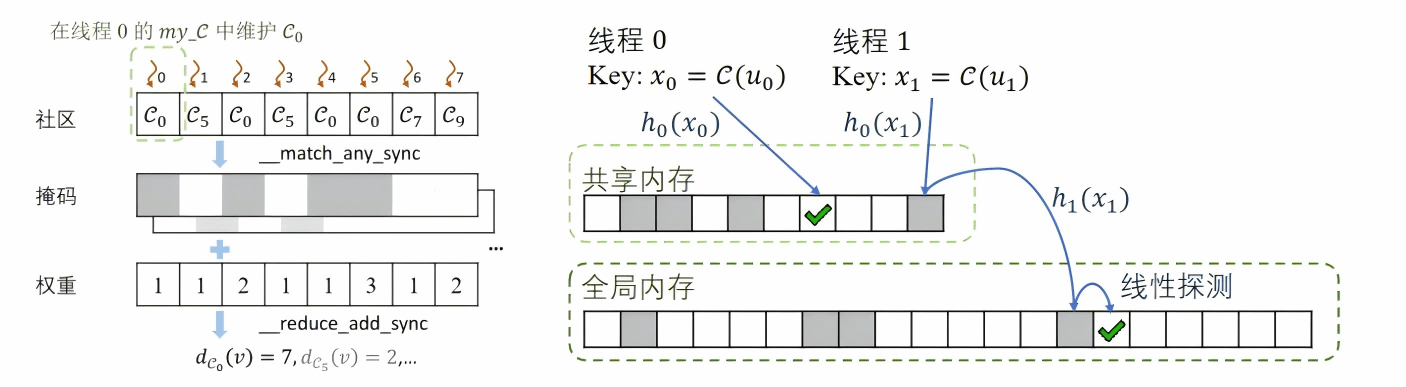
图3 两种内核
实验验证
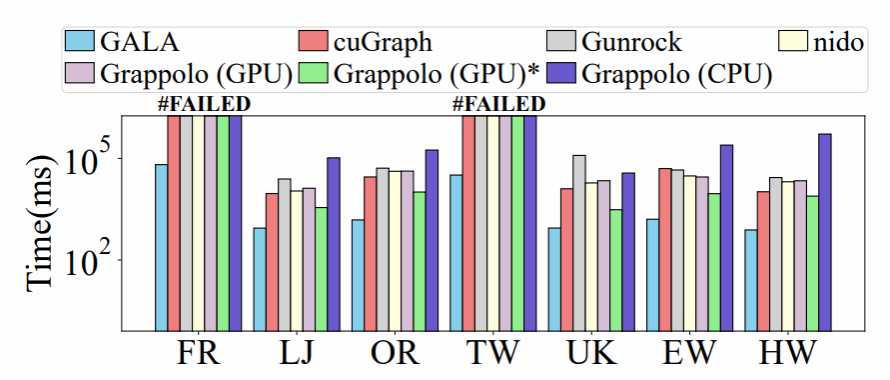
图4 与SOTA对比
如图 4 所示,我们提出的 GALA 在性能上分别比 cuGraph、Gunrock、nido、Grappolo(GPU)、Grappolo(GPU)* 和 Grappolo(CPU) 平均快 22×、62×、26×、28×、7× 和 288×。GALA 的卓越性能不仅归功于新颖的计算与内存优化策略,还得益于我们高度优化的实现,其充分利用了底层 GPU 硬件架构的优势。此外,GALA能够在大约一分钟内处理两个大规模图数据集(FR 和 TW),而其他实现则遭遇了运行时失败(#FAILED)。


 English
English