菠菜担保平台王智彬老师课题组与华为技术有限公司合作,在计算机体系结构顶会ASPLOS 2025上发表论文,提出面向昇腾架构的组件化Roofline模型及算子性能优化方法,攻克AI算力瓶颈!
论文地址:https://doi.org/10.1145/3676641.3716243
研究背景
随着深度学习的发展,许多大型模型不断涌现并在众多任务中表现出色,如 Llama 3、DeepSeek、Qwen 和 OpenSora等等。为了加速大模型的训练和推理,更好地提供庞大的算力支撑,许多公司开发了各自的领域专用架构(DSA),包括英伟达GPU、华为 Ascend NPU、谷歌 TPU 和寒武纪MLU等。面对不同的模型和DSA,释放硬件性能,更好地服务模型是研究者共同的目标。在加速模型训练或推理的过程中,算子的性能至关重要,因此本研究中,我们主要关注基于Ascend架构的算子性能优化。
实际上,对于英伟达GPU而言,可以通过性能profiling来协助分析和优化算子性能,常见的Nsight Compute 工具,正是用来帮助用户发现性能问题并提供建议。那么,面对Ascend芯片,我们该如何应对?为什么我们不直接复用GPU算子性能优化方案呢?这主要是因为芯片架构上的巨大不同。
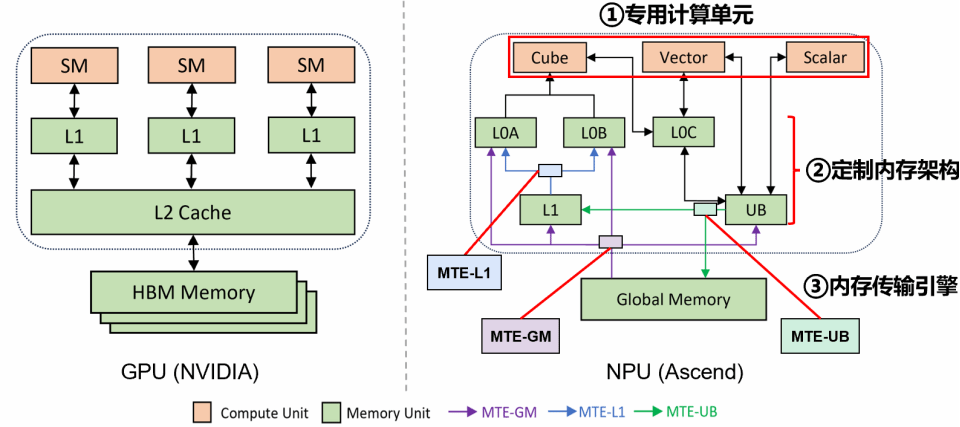
图1 GPU与Ascend架构对比
总的来说,Ascend 架构在带来更高的性能上限和更灵活操作的同时,也带来了更多的瓶颈可能,包括计算单元、MTE单元、指令流水线等。那么如何分析Ascend算子性能呢?
核心挑战
我们首先想到的是,利用在传统的CPU和GPU上广泛使用的Roofline模型进行分析,但是却因为以下问题导致难以适配Ascend芯片:
· 组合爆炸:首先在Roofline模型中,我们需要为每种计算精度和传输构建一条roofline,因此对于Ascend来说,需要分析180种精度-传输组合,导致复杂性超出预期。
· 串行冲突误判:其次,现有的Roofline模型中假设不同的计算和传输都是并行的,忽略了Ascend中计算/MTE 单元内部的顺序性,将会导致错误的分析。例如,由于图2中 INT8 和 FP16 计算是顺序执行的,Roofline模型会误认为它们在整个时间内的利用率仅为 33% 和 67%,得出利用率不足的错误结论。
因此,我们需要解决包括分析中的复杂性和错误,提供简化和准确的操作员性能分析,并为算子优化提供有效指导。

图2 现有Roofline的问题
解决方案
我们提出了针对Ascend架构的算子优化系统,整个流程分为四个步骤:
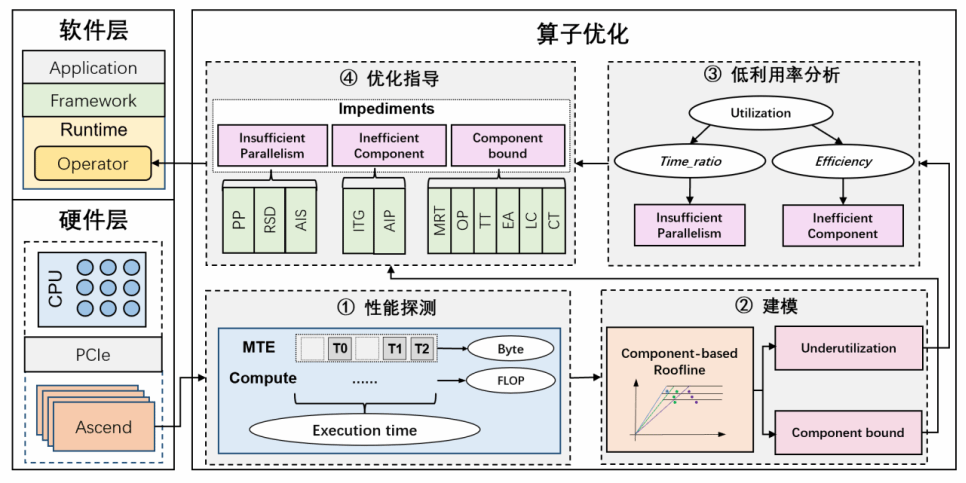
图3 算子优化全流程
· 性能探测:首先,我们收集关键性能指标,以便进一步分析。
· 性能建模:然后,我们改进传统的 Roofline 模型,使其更好地适配 Ascend 架构。
· 低利用率分析:接下来,我们深入研究算子的瓶颈,找出利用率不足的原因。
· 优化指导:最后,根据分析结果提供优化建议,我们分享实际案例研究,展示这些优化在实践中是如何发挥作用的。
实验验证
算子优化:下表总结了在MobileNetV3 模型推理中的算子性能瓶颈,并提出了针对性的优化建议。实验结果表明经过上述优化,这些算子性能提升了1.06倍到4.31倍不等,整体推理时延从8642微秒下降至7157微秒。
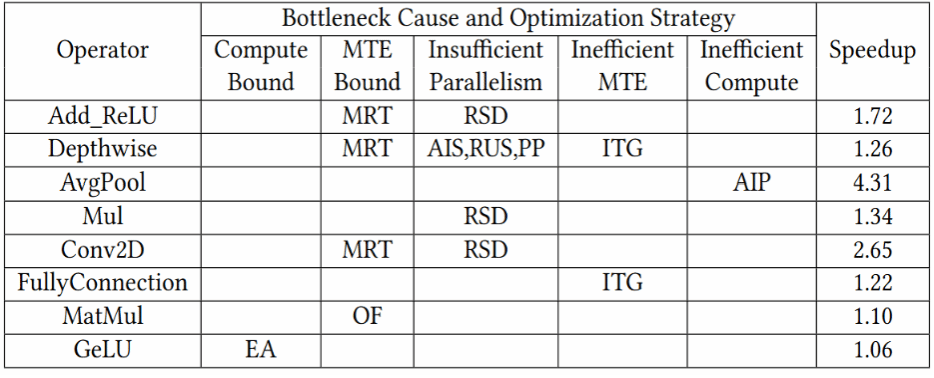
图4 算子优化加速
端到端优化:下图展示了对不同模型(如ViT、GPT2、Llama、DLRM)的端到端训练优化结果,包括算子计算时间和整体训练时间(包含单次迭代中的通信和I/O时间)。很明显,通过算子优化,每个模型的算子计算时间都大幅减少,速度提高了1.08倍到2.70倍。从而整体训练时间也有一定程度的下降。不过,由于数据预处理和通信等因素的影响,加速比略低,从1.07倍到2.15倍不等。总的来说,这些结果证明了算子优化的有效性。
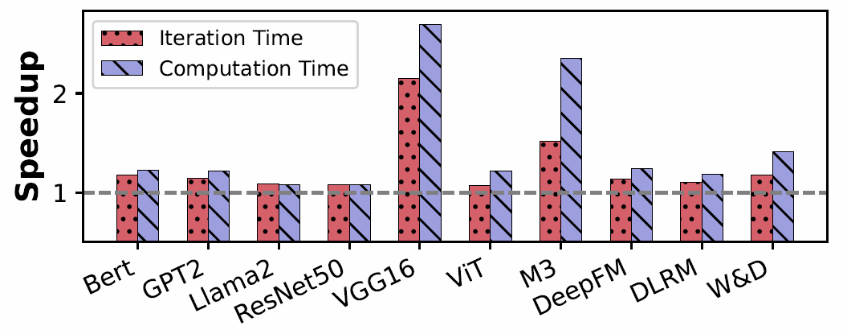
图5 端到端训练优化加速
未来方向
扩展到其他DSA芯片:尽管基于组件的Roofline模型最初是为Ascend架构设计的,但其方法论也适用于其他DSA。例如,Google TPUv5在内存和计算组织上也有类似的改进,包含异构计算单元(如矩阵乘法单元、向量单元和标量单元)以及不同的内存传输路径(如统一缓冲区和权重FIFO)。未来计划将基于组件的Roofline模型扩展到更多DSA,以支持更广泛的硬件架构。
硬件详细分析:由于硬件性能分析的限制,当前研究未能完全解释软件实现如何引发硬件相关问题(如存储体冲突、双缓冲和内存分块)。计划深入研究硬件架构及其与软件栈的交互,包括逐周期分析、硬件操作的详细描述,以及优化如何转化为硬件效率的提升。
训练系统瓶颈分析和优化:当前的研究主要集中在计算算子的性能分析与优化上,然而,训练系统中的性能瓶颈远不止于此。除了计算算子外,数据预处理、I/O操作、CPU利用率、通信开销等因素都可能成为训练系统性能的瓶颈。为了更全面地提升训练系统的效率,下一步的研究将致力于构建一个更完整的性能瓶颈监测、分析和优化系统。


 English
English